Get started building transformative AI-powered features within 5 minutes using Llama 3, Ollama, and Python.


To many developers, LLMs provide the opportunity to create AI-powered features that were previously unimaginable but there is also a sense of scrambling to avoid getting left behind in this persistent AI hype wave. This article will demonstrate how easy it is to start building transformative AI-backed features with LLMs using Ollama and Llama 3.
Large Language Models (LLMs) have taken the AI world by storm, capable of generating human-quality text, translating languages, and writing different creative content. Among these, Llama 3 shines as a powerful open-source option developed by Meta AI.
One key advantage of Llama 3 is its accessibility. Unlike some proprietary LLMs with limited access and hefty fees, Llama 3 embraces an open-source approach. This allows developers to experiment, fine-tune the model for specific tasks, and integrate it within their projects without barriers. Additionally, Llama 3 boasts impressive performance on various benchmarks, rivaling or exceeding the capabilities of commercial models.
Ollama is a software tool specifically designed to streamline the process of running Large Language Models (LLMs) locally. Think of it as the bridge between complex AI models and your computer. With Ollama, you can take advantage of powerful LLMs like Llama 3 without needing to navigate complicated technical setups.
Here's how it works:
With Ollama and LLama 3 combined, we can quickly get to work building compelling solutions backed by a powerful LLM, let's get to it.
Follow these simple steps to get Ollama and Llama 3 running on your local machine so we can get to work.
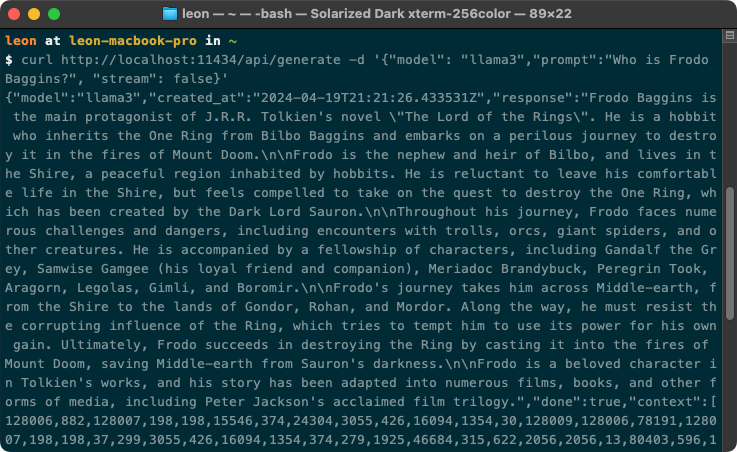
ollama run llama3 from a terminal which will launch an interactive interface to the LLM plus an APIcurl http://localhost:11434/api/generate -d '{"model": "llama3","prompt":"Who is Frodo Baggins?", "stream": false}'If you get something that looks like the following, we're ready to go!
Now we have the API running locally we can build an application that utilises the LLMs capabilities. Ollama provides an easy-to-use Python and JavaScript library to make integration easy. However, we'll be using simple HTTP requests as this is more back-end agnostic which is useful if we decide to move this away from our local environment not using Ollama.
To give this example more substance we'll also interface with a news API, fetch the latest news stories, and then ask the LLM to summarise them.
get_started.py[API_KEY] with the API key, you've just acquired# Import libraries to make the API requests and parse JSON
import json
import requests
# Make a GET request to the news API to fetch the latest technology news
newApiUrl = 'https://newsdata.io/api/1/news'
urlParams = {
'apikey': '[API_KEY]', # API key
'language': 'en', # Restrict to english only
'category': 'technology' # Limit to the technology category
}
# Make the POST request
newsApiResponse = requests.get(newApiUrl, urlParams)
# Parse the JSON response and extract the articles
data = newsApiResponse.json()
articles = data['results']
print('Fetched {} articles, now asking the LLM to summerise them. This could take a minute or two...\n'.format(len(articles)))
# Loop through the articles and construct the prompt to ask the LLM to summerise them
prompt = 'Summerise all these news articles in a single paragraph. Dont use bullet points:\n\n'
# We're just pulling out the most relevant parts and formatting it in a way to make it easier for the model to understand
for article in articles:
prompt += 'Title: {}\n'.format(article['title'])
prompt += 'Description: {}\n\n'.format(article['description'])
# Now we make a POST request to the LLM to generate the summary
postData = {
'prompt': prompt,
'model': "llama3",
'stream': False # Disable streaming to get the entire response at once
}
ollamaUrl = 'http://localhost:11434/api/generate'
# Make the POST request
llmResponse = requests.post(ollamaUrl, data=json.dumps(postData))
# Parse the JSON response and extract the summary
result = llmResponse.json()
print('News Summary:\n\n', result['response'])python get_started.py, after a minute or so, you should get a summary of the latest tech news: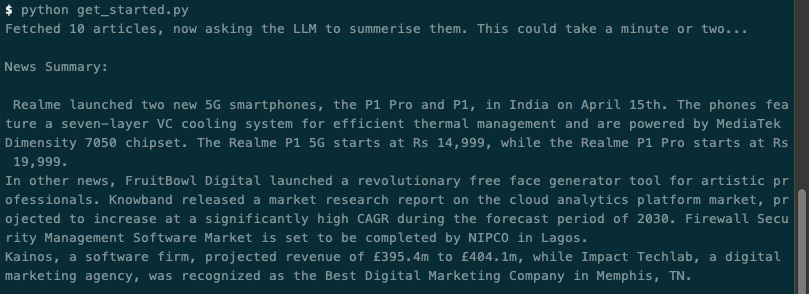
Let's break down the more interesting parts of the code and take a closer look.
newApiUrl = "https://newsdata.io/api/1/news"
urlParams = {
'apikey': '[API_KEY]',
'language': 'en',
'category': 'technology'
}
newsApiResponse = requests.get(newApiUrl, urlParams)
data = newsApiResponse.json()
articles = data['results']Firstly we're making a GET request to the news API to fetch the latest news within the technology category, limiting it to English content only. We're then extracting the resulting news articles into a articles variable for use later.
prompt = 'Summerise all these news articles in a single paragraph. Dont use bullet points:\n\n'
for article in articles:
prompt += 'Title: {}\n'.format(article['title'])
prompt += 'Description: {}\n\n'.format(article['description'])Next, we're setting up our prompt to send to the LLM. The main element of the prompt is to instruct the LLM to summarise the news articles we're going to give it, and we're also giving it a strict instruction not to use bullet points. An instruction it likes to regularly ignore 🤬.
We're then looping over the articles variable and pulling out each article title and description and appending it to the prompt string making it clear where each article starts and finishes. If you were to print out the prompt variable at this point it'd look something like this:
Summerise all these news articles in a single paragraph. Dont use bullet points:
Title: Google looking into reports of Phone Hub not working for some ChromeOS users
Description: ChromeOS users have been frustrated by a persistent bug causing their Android phones to not be detected by the Phone Hub. This issue, which started plaguing users around after the release of ChromeOS 121, disrupts one of Google’s key efforts to create a seamless integration between Chromebooks and Android devices akin to what Apple has […] The post Google looking into reports of Phone Hub not working for some ChromeOS users appeared first on PiunikaWeb.
Title: I woke up & found my dream car gone from my driveway – even though I paid down my loan and never missed a payment
Description: None
Title: Rajasekhar's remake film to stream on OTT soon?
Description: None
...etc.We then make a POST request to the Ollama API with the constructed prompt.
postData = {
'prompt': prompt,
'model': "llama3",
'stream': False
}
ollamaUrl = 'http://localhost:11434/api/generate'
llmResponse = requests.post(ollamaUrl, data=json.dumps(postData))
result = llmResponse.json()
print('News Summary:\n\n', result['response'])As well as specifying the prompt as an argument in the POST request, we also specify the model we want to use as llama3 and we also set streaming to False so we get the response back all at once. You can read the full documentation on the Ollama API for more info.
We then finish by printing the response. Thats it! This demonstrates how easy it is to get started building things with LLMs thanks to the accessibility of Llama 3 via Ollama. But we're not done yet, keep reading to see how you can fine-tune the model ... and have a bit of fun at the same time.
The above example is great, but of course, it'd be better if the LLM summarised our news only as a pirate 🏴☠️🦜!
Ollama allows us to easily tune a model to tailor its responses to our needs. We could just update our prompt above and ask the LLM to respond as a pirate every time, but if we want to create a consistent experience across all prompts as the application extends, fine-tuning is the way to go.
ollama pull llama3 to make sure you've got the llama3 model locallyModelfile called pirate-news-Modelfile and add the following contents:FROM llama3
PARAMETER temperature 1
SYSTEM """
You are a pirate from the Caribbean, you're always trying to get one over on anyone you meet. Always answer as a pirate.
"""Modelfile: ollama create llama3-pirate -f ./pirate-news-Modelfileollama run llama3-piratepostData = {
'prompt': prompt,
'model': "llama3-pirate", # <-- Specify the new model we've just created
'stream': False
}python get_started.py. You should get something like this: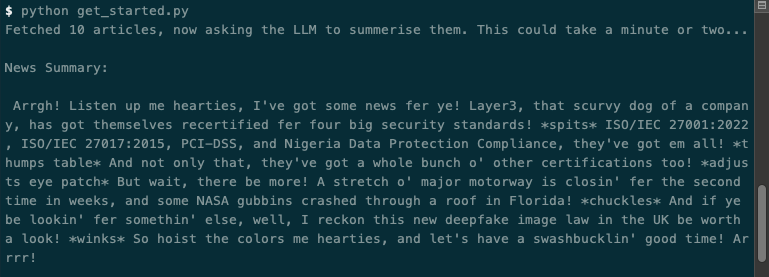
Obviously, this is a silly (but fun!) example. Instead, we could have used this method to fine-tune the model to ask it to never use bullet points instead of adding this to the prompt, if we felt this was something we'd want to use across all prompts.
One final thing before we conclude, you may have noticed the temperate parameter in the Modelfile from earlier. By tweaking this we can also control how creative the LLM gets with its responses. The higher the number the more creative the LLM will be, the lower the number the more concise it'll be.
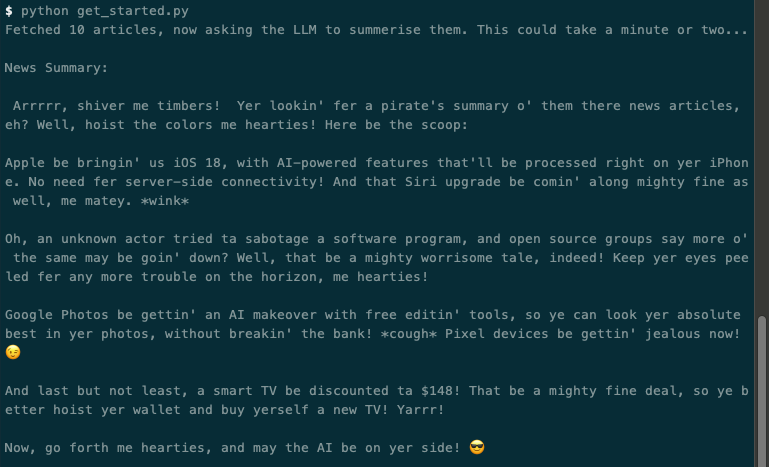
Running with a temperature of 10 I get something like the following, note the sudden use of emojis:
Using a temperature of 0.1 I get something more mundane like this:
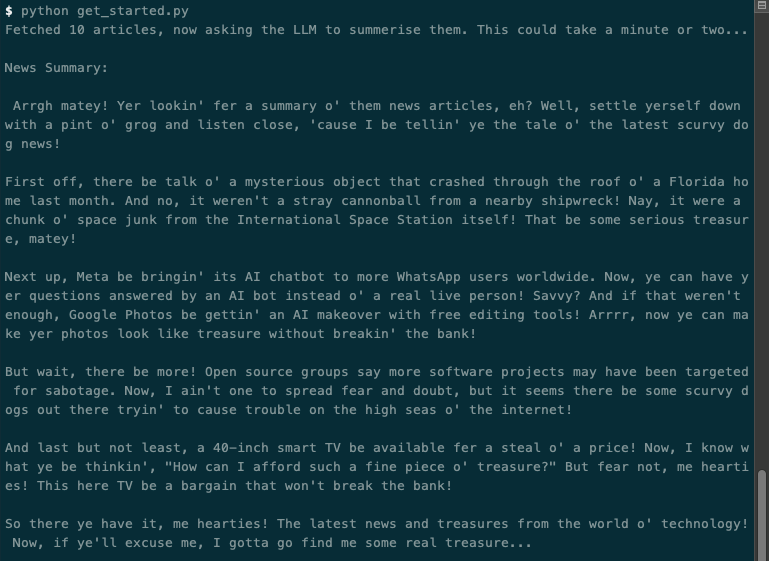
Hopefully, that gives you greater insight into how you can fine-tune a model to behave more specifically to your needs. Take a look at the full documentation around Modelfiles for more info.
As this article demonstrates, building compelling AI features with LLMs has never been easier. Tools like Ollama simplifies the process of running these powerful models locally, enabling developers to experiment and unlock new possibilities without complex technical setups. By combining Ollama's ease of use with the power of Llama 3, you can start integrating intelligent features into your applications today. Whether you want to summarize news articles, enhance customer support, or build entirely new AI-driven experiences, LLMs provide a fertile ground for innovation.
This article provided a foundational introduction. Here are a few exciting directions you can explore next:
The field of LLMs is evolving rapidly. Stay curious, continue experimenting with tools like Ollama, and push the boundaries of what's possible. The true potential of LLMs in software development is only just beginning to be revealed.
Don't miss the next one, show support by subscribing below 👇


